
Dane syntetyczne to algorytmicznie generowane informacje, które wiernie odwzorowują cechy danych rzeczywistych, ale nie zawierają autentycznych punktów danych. Specjaliści ds. danych stosują algorytmy i symulacje do tworzenia zbiorów, które zachowują właściwości statystyczne odpowiadające oryginałom, które imitują. W przeciwieństwie do danych rzeczywistych — pozyskiwanych z faktycznych zdarzeń i mogących zawierać dane wrażliwe — dane syntetyczne są tworzone od podstaw, co eliminuje ryzyko naruszenia prywatności, ponieważ nie zawierają prawdziwych danych osobowych. Początkowo dane syntetyczne miały głównie postać danych niestrukturalnych, takich jak obrazy i filmy. Obecnie obejmują również dane tabelaryczne i tekstowe — przy czym dane tekstowe odpowiadają za około 34,5% rynku w 2024 roku, a dane tabelaryczne za około 50%.
Dane syntetyczne odgrywają kluczową rolę w budowaniu solidnych modeli AI i uczenia maszynowego, zwłaszcza gdy dane rzeczywiste są trudno dostępne lub obarczone problemami związanymi z prywatnością. Umożliwiają tworzenie dużych, niestandardowych zbiorów danych i scenariuszy w kontrolowanych warunkach, co pozwala na precyzyjne testowanie i walidację modeli. Wykorzystuje się je do trenowania systemów wykrywania oszustw, opracowywania nowych metod detekcji, testowania algorytmów handlowych i systemów finansowych, a także do prototypowania produktów.
Globalny i europejski rynek danych syntetycznych: wzrost i zastosowania
Globalny rynek generowania danych syntetycznych został wyceniony na 307,42 miliona USD w 2024 roku, a prognozy wskazują, że do 2037 roku jego wartość przekroczy 18,24 miliarda USD, przy złożonej rocznej stopie wzrostu (CAGR) wynoszącej ponad 36,9% w latach 2025–2037. Inne źródła podają wartość 310,5 miliona USD w 2024 roku i CAGR na poziomie 35,2% w latach 2025–2034 lub 1,27 miliarda USD w 2024 roku i CAGR 12,14% w latach 2025–2035. Niezależnie od rozbieżności w wycenach, wszystkie raporty wskazują na bardzo dynamiczny wzrost tego sektora.
Głównym motorem wzrostu jest rosnące zapotrzebowanie na trenowanie modeli AI i ML. Segment treningu modeli AI/ML odpowiadał za ponad 31% udziału w rynku w 2024 roku i ma przekroczyć 2 miliardy USD do 2034 roku. Do innych kluczowych zastosowań należą ochrona prywatności, zarządzanie danymi testowymi, analityka danych i wizualizacja. Segment zarządzania danymi testowymi ma utrzymać największy udział — około 35%. Pod względem typu danych dominują dane tekstowe (około 34,5% udziału w 2024 roku). Europa, z wartością 0,32 miliarda USD w 2024 roku, ma osiągnąć 1,02 miliarda USD do 2035 roku, co wskazuje na silne inwestycje w technologie danych w różnych branżach.

Dane syntetyczne a prywatność danych w Polsce (RODO)
Rozwój generatywnej AI, w tym dużych modeli językowych (LLM), wywołuje poważne obawy dotyczące ochrony danych osobowych i prywatności. Modele te często „skrobią” niemal cały Internet i mogą generować dane osobowe podlegające RODO. Eksperymenty wykazały, że możliwa jest ekstrakcja wrażliwych informacji z LLM. Nieprawidłowe, a nawet prawidłowe, lecz niepożądane ujawnianie informacji może prowadzić do naruszenia prywatności osób.
W Polsce, podobnie jak w innych krajach UE, organy nadzorcze, takie jak Urząd Ochrony Danych Osobowych (UODO), prowadzą dochodzenia w sprawie potencjalnych naruszeń RODO przez generatywną AI. UODO od dawna interesuje się zagadnieniami związanymi ze sztuczną inteligencją i podkreśla, że nowoczesne systemy AI nie zwalniają administratorów ani podmiotów przetwarzających dane z obowiązku przestrzegania RODO. Urząd zajmuje się również skargami dotyczącymi przetwarzania danych osobowych przez twórców ChatGPT (OpenAI). Prezes UODO, Mirosław Wróblewski, zaznaczył, że ochrona danych osobowych stanowi integralną część AI Act, a jej zapewnienie będzie poważnym wyzwaniem dla organów ochrony danych.
Główne wyzwania prawne to zgodność z RODO w kontekście profilowania i zautomatyzowanego podejmowania decyzji (Art. 22 RODO), niewystarczająca przejrzystość algorytmów oraz brak kompleksowych regulacji dotyczących odpowiedzialności cywilnej za szkody spowodowane przez systemy AI. Nowe regulacje UE, takie jak AI Act (obowiązujący częściowo od lutego 2025 roku, w pełni od sierpnia 2026) i Data Act (obowiązujący od września 2025), wprowadzają dodatkowe wymogi w zakresie dokumentacji, klasyfikacji systemów AI, przejrzystości oraz odpowiedzialności za dane generowane przez urządzenia IoT. Data Act uzupełnia RODO i ma na celu ułatwienie sprawiedliwego podziału wartości generowanej przez dane.
W tym kontekście dane syntetyczne stają się kluczowym czynnikiem umożliwiającym innowacje AI w świetle regulacji RODO. RODO/GDPR oraz nadchodzące AI Act i Data Act nakładają istotne ograniczenia na wykorzystanie danych rzeczywistych, zwłaszcza wrażliwych danych osobowych, do trenowania i testowania modeli AI. Mogłoby to hamować rozwój innowacji. Dane syntetyczne oferują jednak rozwiązanie, które pozwala tworzyć duże, różnorodne i realistyczne zbiory danych bez ryzyka naruszenia prywatności. Dzięki temu regulacje nie są przeszkodą, lecz katalizatorem adopcji danych syntetycznych, które z kolei umożliwiają dalszy rozwój AI. Pokazuje to, że dane syntetyczne nie są jedynie „obejściem” regulacji, lecz strategicznym narzędziem do budowy etycznej i zgodnej z prawem sztucznej inteligencji.
Dane syntetyczne są zgodne z wymogami RODO, ponieważ nie zawierają rzeczywistych danych osobowych, co minimalizuje ryzyko naruszenia prywatności. Umożliwiają firmom, w tym bankom, generowanie dużych zbiorów danych potrzebnych do trenowania modeli ML bez naruszania przepisów prawnych i zasad etycznych. Testowanie z użyciem danych syntetycznych wspiera zgodność z regulacjami takimi jak RODO, pozwalając na walidację obsługi danych wrażliwych bez ujawniania rzeczywistych informacji osobowych na etapie rozwoju. Praktyki takie jak dane syntetyczne, anonimizacja/pseudonimizacja oraz federated learning są wdrażane w Polsce, szczególnie w sektorze bankowym i ochronie zdrowia, by sprostać wyzwaniom związanym z prywatnością i dostępnością danych.
Kluczowe korzyści i zastosowania danych syntetycznych w kontekście AI/ML i prywatności
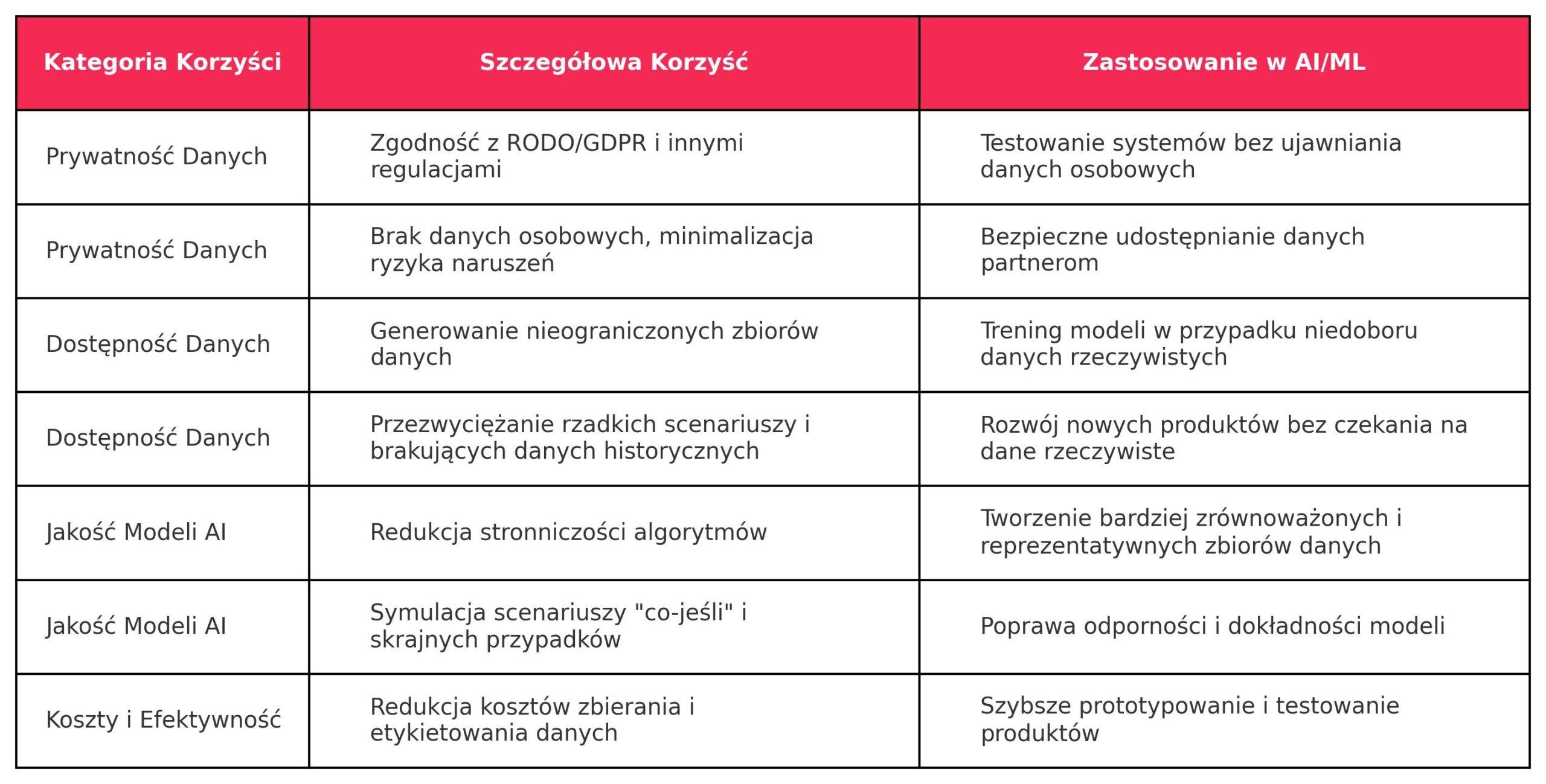
Adopcja danych syntetycznych w Polsce, choć nadal na wczesnym etapie, niesie ze sobą szereg korzyści i wyzwań.
Zalety:
- Przezwyciężanie niedoboru danych: Dane syntetyczne pomagają rozwiązać problem braku wystarczającej liczby danych do trenowania modeli i testowania systemów, szczególnie w wyspecjalizowanych dziedzinach lub dla rzadkich scenariuszy. Organizacje mogą generować nieograniczone ilości danych syntetycznych, aby wypełnić te luki.
- Redukcja stronniczości algorytmów: Dane syntetyczne mogą być projektowane tak, by zrównoważyć niedostatecznie reprezentowane klasy, co prowadzi do bardziej sprawiedliwych i mniej stronniczych modeli uczenia maszynowego.
- Symulacje scenariuszy: Umożliwiają tworzenie scenariuszy typu „co-jeśli”, które nie występują w zebranych danych, pomagając systemom przygotować się na nietypowe sytuacje lub przyszłe zdarzenia.
- Oszczędności: Generowanie danych syntetycznych znacząco ogranicza zasoby potrzebne do pozyskiwania i etykietowania danych, ponieważ można je tworzyć szybko i na dużą skalę, co obniża koszty.
Wyzwania:
- Jakość i realizm danych: Kluczowe jest zapewnienie, że dane syntetyczne wiernie odzwierciedlają złożoność rzeczywistego świata. Algorytmy mogą generować wzorce, które nie odpowiadają realnym scenariuszom, co może prowadzić do słabej wydajności modeli trenowanych na takich danych w praktycznych zastosowaniach. Utrzymanie realizmu i unikanie stronniczości w danych syntetycznych to warunki konieczne dla ich wartości biznesowej. Choć dane syntetyczne oferują wiele korzyści, ich skuteczność zależy bezpośrednio od jakości i realizmu — muszą dokładnie oddawać złożoność danych rzeczywistych. Istnieje ryzyko „model collapse” oraz możliwość przeniesienia lub wręcz wzmocnienia stronniczości obecnej w danych źródłowych, co stanowi poważne wyzwanie. Firmy muszą więc inwestować w zaawansowane techniki generowania i rygorystyczne procesy walidacji, aby zapewnić faktyczną użyteczność danych syntetycznych. Samo „generowanie danych” nie wystarczy — kluczowe jest tworzenie wysokiej jakości, reprezentatywnych danych, co wymaga specjalistycznej wiedzy i odpowiednich narzędzi.
- Kwestie etyczne: Wykorzystanie danych syntetycznych w wrażliwych obszarach, takich jak diagnostyka medyczna, może być problematyczne — niedokładności mogą prowadzić do poważnych ryzyk. Choć dane są syntetyczne, mogą potencjalnie ujawniać informacje wrażliwe, jeśli proces ich generowania nie jest odpowiednio nadzorowany.
- Ryzyko „model collapse”: Trenowanie modeli wyłącznie na danych syntetycznych wiąże się z ryzykiem „model collapse” — degradacji wydajności modelu z powodu braku rzeczywistej zmienności obecnej w danych naturalnych.
- Brak funduszy VC i dostępu do danych wysokiej jakości: W Polsce wyzwaniem pozostaje ograniczony dostęp do wysokiej jakości danych oraz brak funduszy venture capital dedykowanych AI, co stanowi barierę szczególnie dla małych firm.
Dane syntetyczne stają się kluczowym narzędziem w rozwoju sztucznej inteligencji, szczególnie w kontekście rosnących wymagań regulacyjnych, takich jak RODO, AI Act i Data Act. Pozwalają tworzyć realistyczne i zgodne z prawem zbiory danych bez naruszania prywatności, co ma istotne znaczenie dla sektorów takich jak bankowość i ochrona zdrowia. Globalny rynek danych syntetycznych dynamicznie rośnie, a w Polsce, mimo wczesnego etapu adopcji, obserwuje się rosnące zainteresowanie tą technologią. Korzyści obejmują m.in. przezwyciężanie niedoboru danych, redukcję stronniczości i oszczędności kosztowe, ale wyzwaniem pozostają jakość danych, kwestie etyczne i ograniczony dostęp do finansowania. W dłuższej perspektywie dane syntetyczne mogą odegrać strategiczną rolę w budowie etycznej, bezpiecznej i zgodnej z prawem sztucznej inteligencji.







