
W 2020 r. świat zapomniał o sezonowej grypie przez pandemię koronawirusa. Według danych CDC[1] (amerykańskiego stowarzyszenia Ośrodków Kontroli i Zapobiegania Chorób) zachorowalność na grypę w USA od 1 marca do 16 maja 2020 r. spadła o 98% w porównaniu z sezonem 2019-2020. Jest to najniższy poziom międzysezonowej cyrkulacji wirusa. Zgodnie ze światowymi danymi WHO, w sierpniu 2021 r. globalna aktywność grypy pozostaje na niższym poziomie niż oczekiwano, co, według organizacji, może być związane z przestrzeganiem dystansu społecznego i noszeniem masek.
Jednakże grypa nie powiedziała ostatniego słowa. Niektórzy epidemiolodzy oczekują zwiększenia zachorowalności już w sezonie 2021-2022. Może ona być bardziej agresywna, ponieważ nasz system immunologiczny, przyzwyczajony do corocznej epidemii, stracił czujność. Do tego, jak mówią eksperci, przez deficyt informacji w sezonie 2020-2021, trudniej jest przewidzieć sytuację i określić, jakie odmiany wirusa będą się rozprzestrzeniały.
Czy rzeczywiście tak trudno jest przewidzieć epidemię grypy? Przecież towarzyszy nam ona już wiele dekad w odróżnieniu od COVID-19 i wszyscy o niej wiedzą. Dowiedzmy się, o co w tym chodzi – z użyciem minimalnej liczby potrzebnych równań i trudnych terminów.
Czym jest epidemia z naukowego punktu widzenia
Kiedy słyszymy słowo „epidemia”, zwykle wyobrażamy sobie zjawisko z bardzo poważnymi skutkami. Najczęstsze skojarzenia to: codzienne komunikaty w wiadomościach, karetki z włączonymi syrenami na ulicach, rygorystyczne środki ochrony. Z punktu widzenia nauki, epidemia to jednak o wiele mniej drastyczne zjawisko.
Wśród wielu definicji epidemii najpopularniejszą w środowisku naukowym jest ta, którą stosuje CDC. Według niej, epidemia to zwiększenie, często nagłe, liczby przypadków zachorowania w porównaniu z tym, które zwykle jest przewidywane dla danej populacji na danym terenie.
Wielka zaraza w Londynie, która w latach 1665-1666 odebrała życie 100 tysięcy mieszczan (20% ludności), była epidemią. Intensywny atak grypy w 1978 r.[2] w zamkniętej szkole dla chłopców na północy Anglii, w wyniku którego zachorowało 512 z 763 uczniów, również była epidemią. Stosunkowo niedawny przypadek we Francji[3], kiedy 7 gości na weselu zaraziło się wirusowym zapaleniem wątroby typu E, zjadłszy tradycyjną korsykańską kiełbasę ze świńskiej wątroby (figatellu), również uważa się za epidemię.
Ogromną część epidemii większość z nas przechodzi niezauważalnie. Według danych WHO od 2011 r. do 2017 r. na świecie zanotowano od 164 do 213 epidemii: dżumy, cholery, dengi, wirusa Zika i innych.
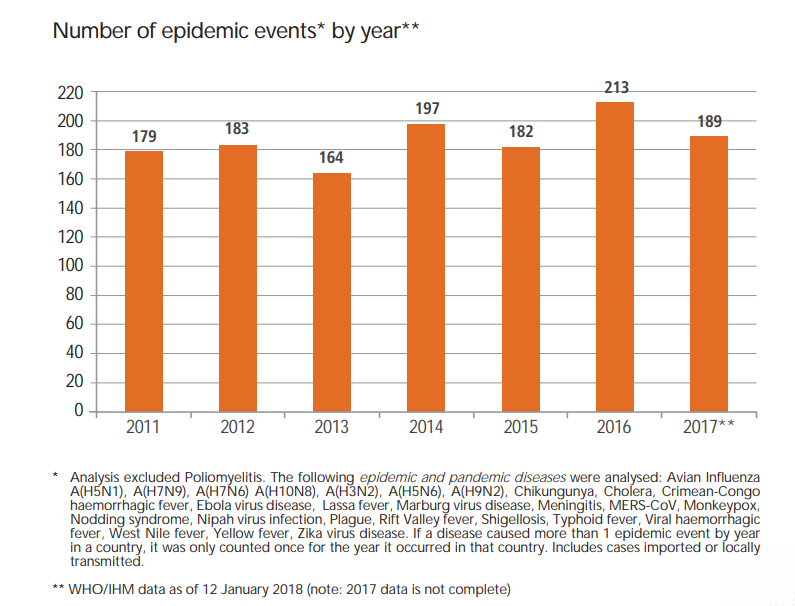
Ogólnie mówiąc, epidemii jest tak dużo, że logiczne jest do nich podejście systemowe. Takie, które będzie wykorzystywało modelowanie matematyczne, aby zniwelować jej skutki.
Wirus grypy i pierwsza trudność w modelowaniu
Grypa to wirus, dla którego naturalnym środowiskiem są zwierzęta: ptaki, świnie, konie, a także ludzie. Istnieją cztery typy grypy: A, B, C i D, z których u ludzi spotyka się pierwsze trzy, przy czym typ C jest bardzo rzadki i zwykle bezobjawowy. Najniebezpieczniejszym, prowadzącym do pandemii, jest wirus z grupy A. Dzieli się on na podtypy w zależności od połączenia białek (antygenów) na swojej powierzchni, które zapewniają przenikanie do komórki ludzkiej hemaglutyniny (HA) i neuraminidazy (NA).
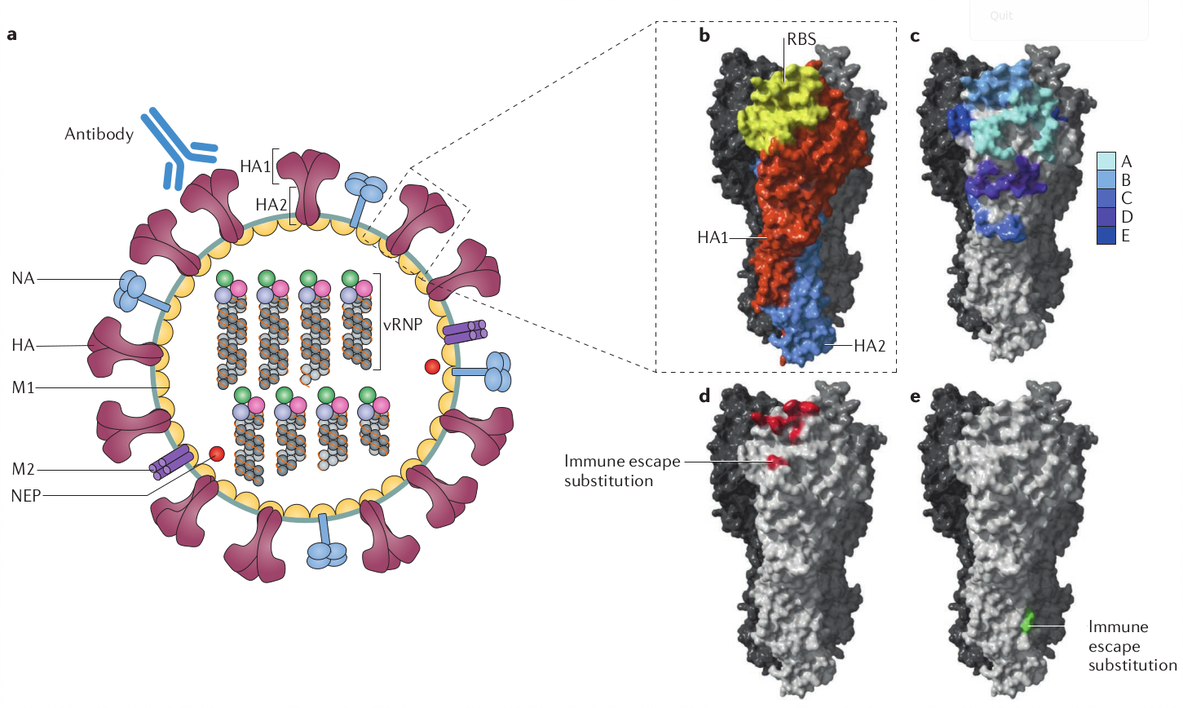
Cząstka wirusa (wirion) grypy typu A i B[4]
Na pewno znacie te kombinacje: H1N1, H3N2, H5N7. Litera „H” oznacza tu hemaglutyninę, a „N” – neuraminidazę. Obecnie znanych jest 18 typów hemaglutyniny i 11 neuraminidazy, możliwa jest np. wariacja H18N11.
Warto odnotować, że grypa to wirus RNA, co oznacza wysokie prawdopodobieństwo mutacji. W procesie replikacji (kopiowania) RNA, przy przenikaniu do komórki, dochodzi do większej liczby pomyłek przez zmiany w strukturze hemaglutyniny i neuraminidazy. Mówiąc prościej, w komórce gromadzi się nie ten wirus, który oczekuje na spotkanie z organizmem. To nowa odmiana, przed którą nie ma się odporności, nawet jeśli organizm przeszedł grypę miesiąc wcześniej. Zapamiętajmy tę ważną dla modelowania cechę.
Najpopularniejszy model i inne trudności przy modelowaniu
Przy modelowaniu z reguły patrzy się na następujące charakterystyki, które pomagają dokonać obliczeń dotyczących obciążenia służby zdrowia:
● początek epidemii;
● czas do wystąpienia szczytu epidemii;
● intensywność szczytu;
● liczba ludzi, którzy zachorują w czasie epidemii.
W 1927 r. szkoccy uczeni, William Kermack i Anderson McKendrick zaproponowali model SIR, który do dziś uważa się za bazowy. Zgodnie z nim, cała populacja podzielona jest na trzy grupy: podatnych na infekcję (Susceptible), zainfekowanych (Infectious) i ozdrowieńców z nabytą odpornością (Recovered).
Od razu można powiedzieć, że przy grypie czynnik ozdrowieńców (Recovered) nie zawsze jest miarodajny. Przypuśćmy, że chory się wyleczył, zyskał antyciała, a następnie, pewny swego zdrowia, pojechał do biura metrem. Po dwóch dniach musiał ponownie położyć się do łóżka, z temperaturą, bólem głowy i innymi objawami grypy. Dlaczego? Ponieważ w jego otoczeniu krążyły dwie odmiany, różniące się kombinacją hemaglutyniny i neuraminidazy. Jednej z nich system immunologiczny w porę nie rozpoznał. Do tego organizm osłabł po walce z wcześniejszą odmianą – możliwe, że ta okoliczność doprowadzi do cięższego przebiegu choroby, wezwaniu pogotowia i hospitalizacji.
Model SIR opisuje się układem trzech zróżnicowanych równań:
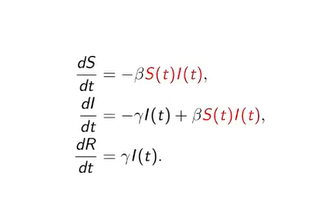
Z punktu widzenia matematyki to, co oznaczono na czerwono, oznacza, że mamy do czynienia z nieliniowością. Nie będziemy mogli znaleźć rozwiązania w sposób analityczny, tworząc formuły dzięki znanym nam funkcjom. Trzeba stosować rozwiązanie liczbowe. Współczynniki, które tu występują, określają szybkość przejścia z jednej grupy do drugiej: β– ze zdrowych do chorych, γ – z chorych do wyzdrowiałych.
W ostatecznym rachunku otrzymamy tożsamość:
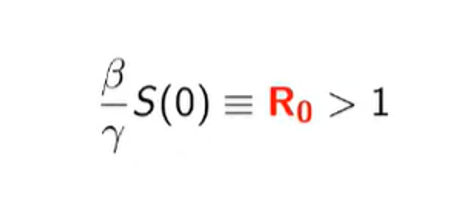
S(0) to liczba ludzi, którzy mogą zachorować przed początkiem epidemii. Jest to również indeks reprodukcji R0, znany dobrze wszystkim, którzy obserwowali rozwój pandemii COVID-19. Oznacza on, ilu ludzi może zarazić jeden chory. Przy R0 powyżej jedynki rozwija się epidemia. Jeśli indeks jest mniejszy niż jedynka, to epidemia wygasa.
W modelu SIR zakłada się, że ludzie tworzą nieprzerwane, jednorodne środowisko. Jak gaz lub ciecz. Populację uważa się za stałą, nie bierze się pod uwagę ubytku ludności – naturalnego bądź przez wirusa – i jej przyrostu. W praktyce prowadzi to do poważnego błędu w obliczeniach.
Pamiętacie przykład z grypą w zamkniętej szkole dla chłopców? Nawet jeśli przy pomocy matematyki stworzy się model sytuacji w szkole z przedziałem ufności (95%), to okaże się, że zachorowało przykładowo 750 uczniów. Wiemy jednak dokładnie, że chorych było 512. R0 jest przykładowo równy 16, a tak naprawdę był równy 1,69. Jeśli w ten sam sposób stworzylibyśmy model sytuacji nie dla jednej szkoły, a, powiedzmy, dla miasta czy kraju, to nasze prognozy wywołałyby tysiące pytań. Jak to w końcu jest?
Trzeba wiedzieć, że grypa nie rozwija się błyskawicznie. Istnieje okres utajony i okres inkubacyjny. Od początku zarażenia się do pojawienia się objawów klinicznych mijają średnio 2 dni (przy COVID-19, jak wiecie, do 14 dni). Do tego okres inkubacyjny częściowo nakłada się z okresem zarażania: chory jeszcze nie wie o swojej infekcji i zaraża innych.
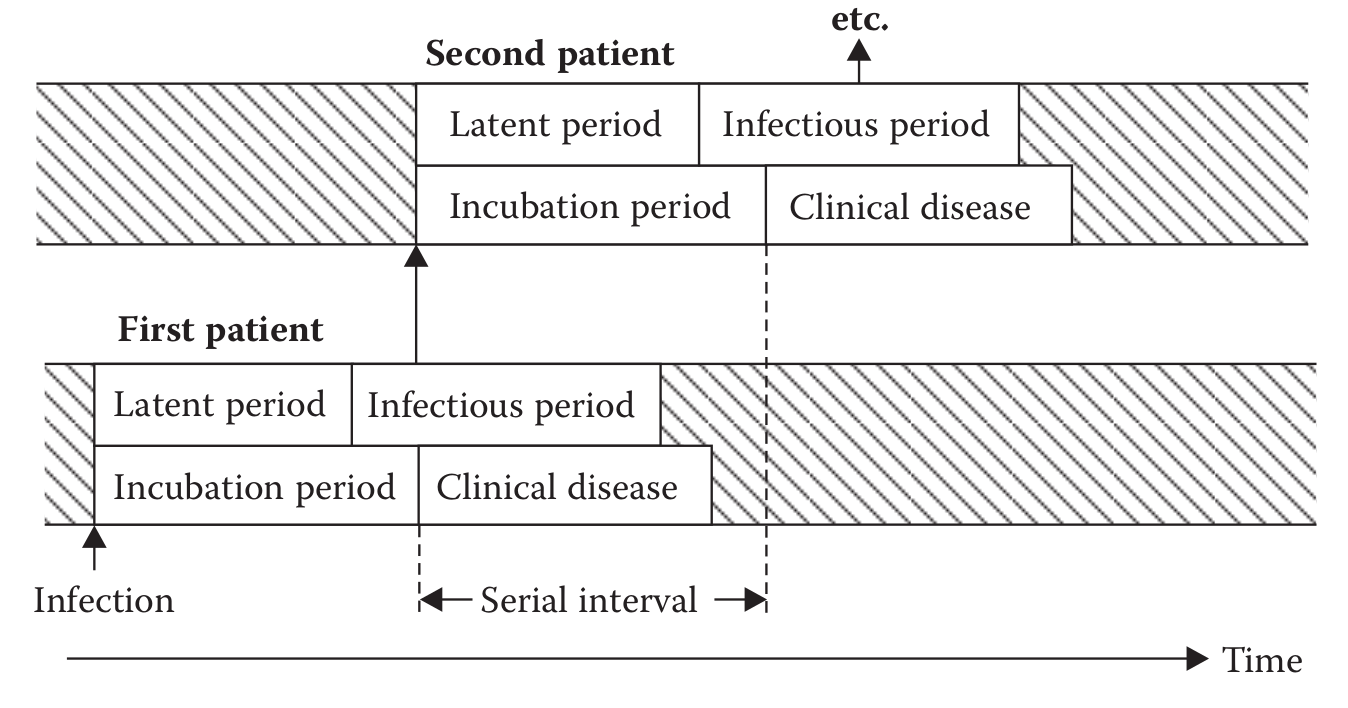
W celu uwzględnienia zarażonych w okresie inkubacyjnym w modelu SIR wprowadza się grupę E (Exposed). Modyfikowany model SEIR to nowy układ równań, nowy współczynnik, lecz R0 tak jak poprzednio wynosi 16.

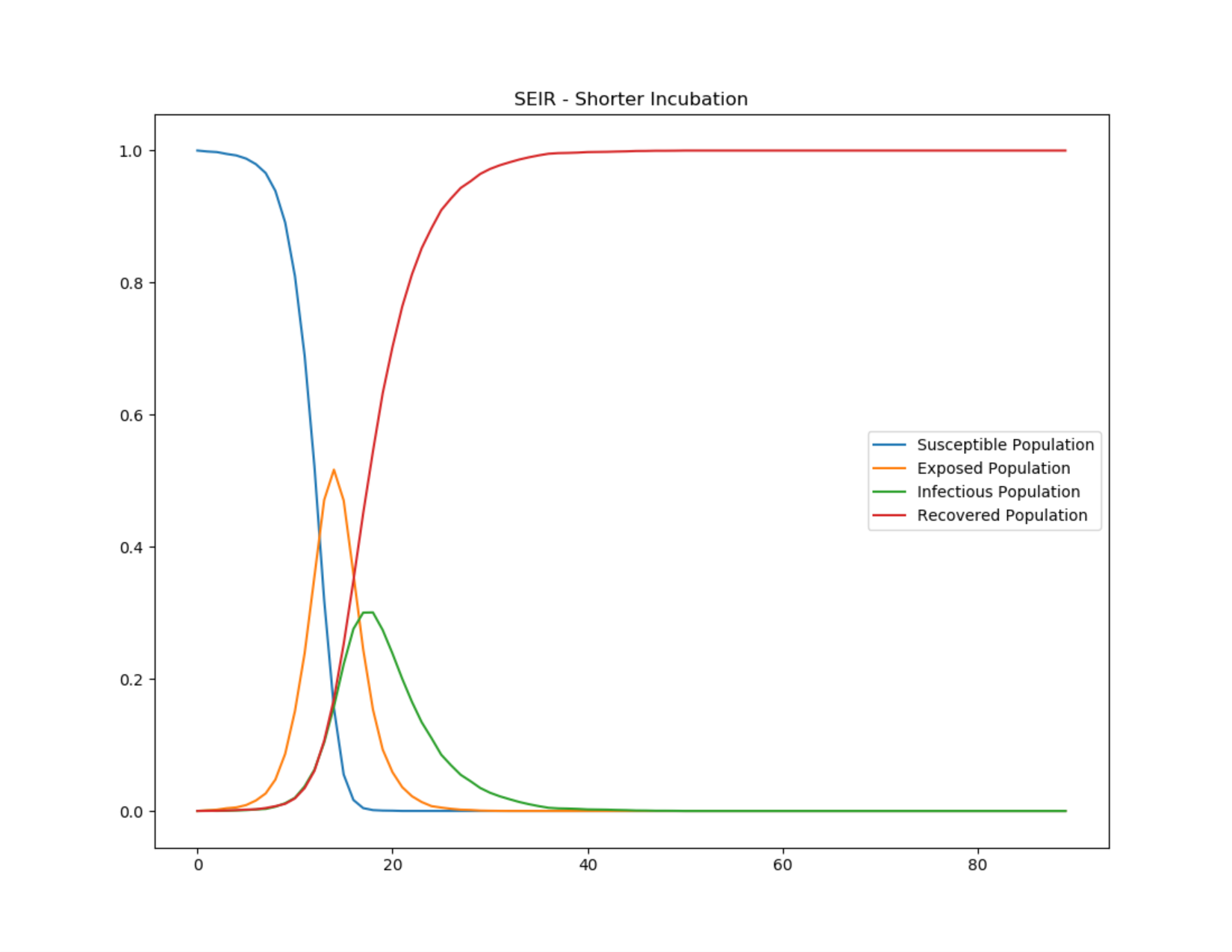
Modelowanie SEIR z 2-dniowym okresem inkubacyjnym [5]
Można jeszcze uwzględnić tych, którzy znajdują się na kwarantannie, i stworzyć model SEIQR, gdzie Q oznacza kwarantannę. Wtedy otrzymamy R0 równy 6-8, który, tak jak poprzednio, daleki jest od realnego 1,69.
Podobnych wariacji modelu SIR jest wiele. Jeśli, np., wziąć pod uwagę liczbę zmarłych, lecz bez kwarantanny, otrzymamy model SEIRD itd. Jednak czegokolwiek byśmy nie uwzględnili, modelowanie SIR nie daje akceptowalnej dokładności. Rzecz w tym, że dowolna modyfikacja modelu jest deterministyczna: nie istnieją dla niej przypadkowe przyczyny. Grypa stanowi masę przypadkowości na każdym etapie, od połączenia się wirusa z komórką do przechodzenia licznych pułapek układu immunologicznego. Zatrzymanie się w naszym organizmie to prawdziwe wyzwanie dla każdego wirionu.
Modele, które uwzględniają przypadkowości
Jeśli liczba podatnych na infekcję i chorych to przypadkowe współczynniki, to model nosi miano stochastycznego. Stara się on odpowiedzieć na pytanie: jeśli w tygodniu „k” wskaźnik „x” to liczba zdrowych, to jakie jest prawdopodobieństwo, że w tygodniu „k+1” wskaźnik ten będzie oznaczał liczbę chorych? I oprócz tego, jakie jest prawdopodobieństwo uniknięcia infekcji (u)?
Kiedy „u” zależy od liczby chorych (w tym sensie, że im więcej chorych, tym mniejsze prawdopodobieństwo uniknięcia zarażenia), otrzymujemy model Reeda-Frosta. Jeśli zakładamy, że prawdopodobieństwo zachorowania nie zależy od liczby[6] chorych, to otrzymujemy model Greenwooda.

Są to już bardziej elastyczne modele, nieciągłe – nazywa się je jeszcze modelami rozgałęzień (branching model). Liczba ozdrowieńców spada, prawdopodobieństwo zachorowania w najbliższym tygodniu zmienia się w zależności od sytuacji w poprzednim. Modele stochastyczne zastosowano na szeroką skalę w latach 70. XX w., stale rozwijano je i obecnie ogólnie odnotowują one wysoką zgodność z prognozami różnych infekcji.
Co jeszcze można uwzględnić? Np. to, że ludzie różnie funkcjonują w społeczeństwie. Jedni pięć dni w tygodniu kontaktują się z dziesiątkami kolegów z pracy i ciągle spotykają się z przyjaciółmi, inni w ogóle nie mają przyjaciół i pracują w domu. Istnieje prawdopodobieństwo, że mają oni różne szanse na zachorowanie na grypę, dlatego można rozpatrywać rozprzestrzenianie się infekcji na grafie społecznym. Wygląda on przykładowo tak:

Z takim modelowaniem również są problemy, dlatego że w praktyce nie można stworzyć grafu z wszystkimi kontaktami społecznymi.
Jeszcze jedną trudność przy modelowaniu stanowi wiarygodność danych. Tworzymy prognozy na podstawie obserwacji: pewna liczba osób w pewnym okresie zachorowała, trzeba to uwzględnić. Co jednak oznacza, że zachorowali? Pacjent z symptomami grypy musi iść do lekarza, a lekarz musi przekazać informacje organom nadzorującym:
temperatura powyżej 38 stopni, kaszel, objawy pojawiły się w ciągu 10 dni. Nazywa się to chorobą grypopodobną (ILI, Influenza-like illness).
Aby wykryć przypadki „czystej grypy”, wykorzystuje się termin ILI+[7], oznaczający, że do diagnozy potrzebny jest test, który w wymazie z jamy nosowo-gardłowej ujawni hemaglutyninę, neuraminidazę lub RNA grypy. Później określana jest część przetestowanych osób z wynikiem pozytywnym spośród wszystkich zgłaszających się z objawami grypy. Oczywiście dane te pozwalają tworzyć dokładniejsze modele.
Co jeszcze należy uwzględniać?
Wróćmy do procesu zarażenia. Przy oddychaniu, kichaniu i kaszlu zarażonego do powietrza trafiają cząstki, które dzieli się według rozmiaru: powyżej 5 mikrometrów (Droplet, kropla) i mniej niż 5 mikrometrów (Airborne, kropelka). Jeśli kaszel wydala przykładowo 10 tysięcy cząstek, to kichanie milion. Dlatego należy unikać kontaktu przede wszystkim z kichającymi.
Cząstki poniżej 5 mikrometrów stanowią większość. Prawie bez przeszkód przechodzą przez górne drogi oddechowe i dostają się do płuc. Nie ma tam już nabłonka rzęskowego, gęsto pokrytego śluzem, który jest poważną barierą dla większych cząstek. Są natomiast alweolarne makrofagi neutrofile, gotowe do ataku na dowolny patogen, co prawda, nie zawsze z dobrym skutkiem. Kropelki łatwo przenoszą się w powietrzu i długo osiadają, 4 razy wolniej niż cząstki o rozmiarze 10 mikrometrów.
Poważne znaczenie dla rozprzestrzenienia się wirusa ma szybkość parowania cząstek. Aby wyparowały połowicznie, potrzeba od 0,01 do 10 sekund. Różnica jest związana bezpośrednio z wilgocią: im jest ona niższa, tym szybciej paruje cząstka. Chory w windzie kichnął, wilgoć była niska – cząstka, nie zdążywszy osiąść, wyparowała do rozmiaru kropelki i krąży w powietrzu, póki nie trafi do nosa zdrowego człowieka.
Przypomnijmy sobie, kiedy wilgoć w pomieszczeniach jest minimalna. Np. w Niemczech w lutym i w grudniu jest taka w szczycie sezonu grzewczego. Właśnie dlatego grypa ma wyraźną sezonowość (czego nie ma np. gruźlica). W ten sposób, znajomość dynamiki cząstek aerozolowych pozwala wyjaśnić, dlaczego epidemie powstają w określonych porach roku. Po drugie, pomaga ocenić ryzyko zarażenia.
Zamiast zakończenia
Wiemy wiele o grypie, nawet możemy policzyć, jak „zarażone” cząstki latają w powietrzu i jak parują. Wiemy także jednak, że procesy te mają charakter losowy. Nie można ich wszystkich uwzględnić nawet przy pomocy doskonałych metod matematycznych lub uczenia maszynowego. Tak naprawdę nie modelujemy epidemii, lecz tworzymy prognozy. Całą serię prognoz: nastąpienia epidemii, jej szczytu i intensywności. I im dalej od szczytu, tym dokładność jest mniejsza: w ciągu jednego tygodnia wynosi 75%, a w ciągu dwóch spada do 25%.
Prognozy te, pomimo swych wszystkich wad, są konieczne. Przy pomocy modelu SIR można określić np., że epidemia rozpocznie się w pierwszej dekadzie grudnia, będzie trwać trzy tygodnie, zachoruje milion ludzi, a w jej szczycie będzie 100 tysięcy zarażeń. Pozwoli to służbie zdrowia się przygotować, udostępnić potrzebną ilość lekarstw i miejsc w szpitalach. Dlatego też korzyścią stosowania modeli opartych na prawdopodobieństwie jest pomoc w tworzeniu prognozy uwzględnienia zaszczepionych, prawdopodobieństwa zarażenia się każdej grupy w populacji itd. Póki co, jest to optymalna praktyka, pomagająca walczyć z epidemiami wirusów, które całkiem dobrze znamy.
Aby zrozumieć, który sposób walki z epidemią jest najlepszy, wystarczy spojrzeć na niniejszy grafik:
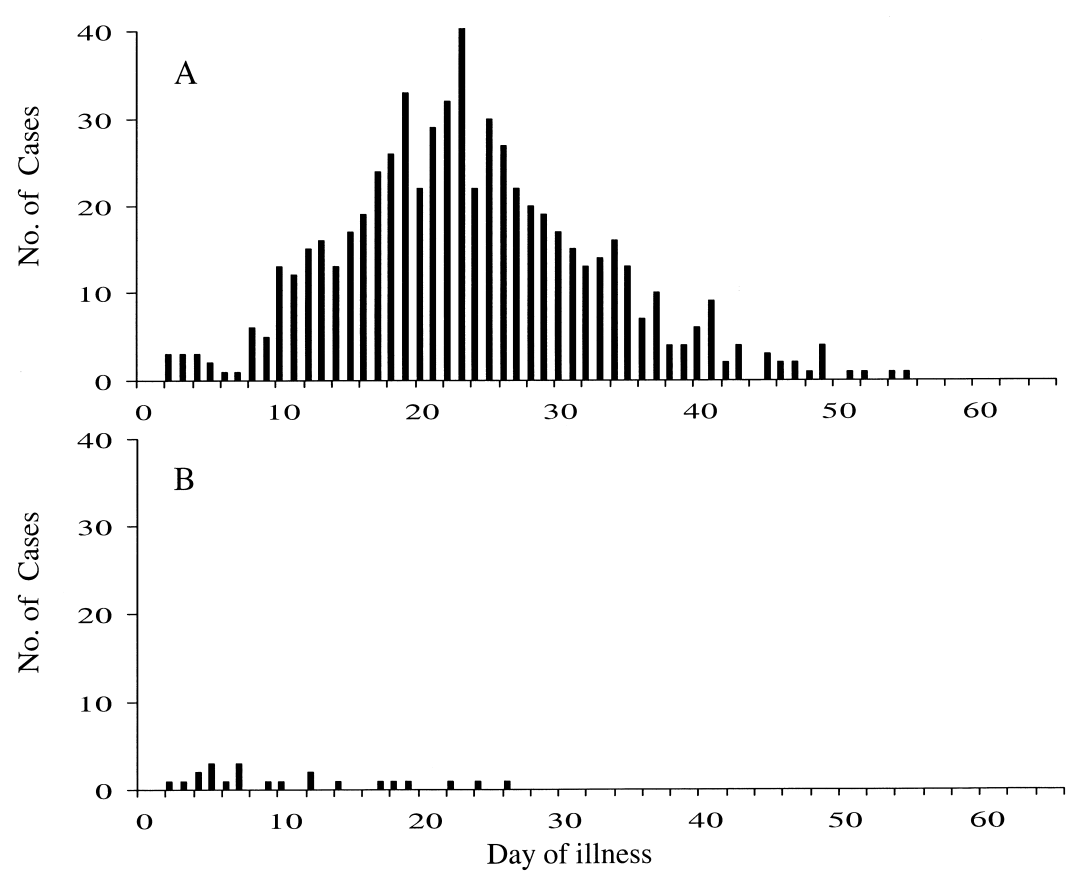
Górny wykres – liczba zarejestrowanych przypadków grypy w populacji, dolny wykres – z uwzględnieniem szczepień.
Wypływa z tego prosta nauka: warto myć ręce, wietrzyć pomieszczenia, włączać nawilżacz, lecz bez szczepienia zwyciężyć epidemię grypy się nie da. I nieważne, który model wykorzysta się do przewidywań.
Jeśli interesuje was, jak matematyka i uczenie maszynowe pomagają w walce z fałszywymi wiadomościami, pogłoskami i teoriami spiskowymi w czasie epidemii, polecamy wykład Presława Nakowa na bezpłatnej konferencji online IT NonStop (18-20 listopada 2021 r.). Presław Nakow to główny pracownik naukowy Katarskiego Instytutu Badawczego Techniki Informatycznej na Uniwersytecie Hamada ibn Chalify w Katarze. Nakow stoi na czele megaprojektu Tanbih, opracowanego we współpracy z Instytutem Technologii w Massachusetts, przy pomocy którego ogłaszane są w szczególności fałszywe informacje o COVID-19.
W programie konferencji jest ponad 40 wykładów i warsztatów specjalistów z https://it-nonstop.net/ firm takich jak np.: Microsoft, AWS, Ocado, Codete, Ciklum, Eleks, SoftServe, Toloka, Yandex, DataArt.
Autor: Anton Dołgich, kierownik oddziału AI, Healthcare and Life Sciences w DataArt
[1] źródło: https://www.cdc.gov/mmwr/volumes/69/wr/mm6937a6.htm
[2] Źródło: https://www.cdc.gov/mmwr/volumes/69/wr/mm6937a6.htm
[3] Źródło: https://academic.oup.com/jid/article/202/6/825/935689
[4] źródło: https://www.nature.com/articles/nrmicro.2017.118
[5] Źródło: https://docs.idmod.org/projects/emod-hiv/en/latest/model-seir.html#id4
[6] Źródło: https://en.wikipedia.org/wiki/Reed%E2%80%93Frost_model#:~:text=The%20Reed%E2%80%93Frost%20model%20is%20one%20of%20the%20simplest%20stochastic,%2C2%2C…)&text=These%20conditions%20remain%20constant%20during%20the%20epidemic.
[7] źródło: https://journals.plos.org/ploscompbiol/article?id=10.1371/journal.pcbi.1006742








